
Глава 1 ПРОИСХОЖДЕНИЕ ДИФФЕРЕНЦИАЛЬНОЙ ПСИХОЛОГИИ
РАЗВИТИЕ СТАТИСТИЧЕСКОГО МЕТОДА
Статистический анализ является одним из основных средств, которые использует дифференциальная психология Гальтон очень хорошо понимал необходимость приспособления статистических методов к процедурам обработки собранных им данных по индивидуальным различиям. Для этой цели он предпринял попытки адаптировать многочисленные математические процедуры. Среди принципиальных статистических проблем, которыми занимался Гальтон, была проблема нормального распределения отклонений (ср. с гл. 2) и проблема корреляции. Что касается последней, то он провел большую работу и в конце концов вывел коэффициент, который получил известность как коэффициент корреляции. Карл Пирсон, который был его студентом, впоследствии разработал математический аппарат теории корреляции. Таким образом, Пирсон внес свой вклад в развитие и систематизацию того, что раньше относилось только к области статистики.
Другим британским ученым, чей вклад существенно повлиял на развитие статистики, был Р.А. Фишер. Работая преимущественно над исследованиями в области сельского хозяйства, Фишер разработал множество новых статистических методов, которые зарекомендовали себя как в высшей степени полезные во многих других областях, включая психологию, и открыли широкие возможности для анализа данных. Его имя больше всего ассоциируется с анализом изменчивости — методом, позволяющим проводить одновременный анализ результатов нескольких вариантов одного и того же эксперимента.
Для квалифицированной интерпретации практически любого исследования в области дифференциальной психологии требуется понимание определенных фундаментальных статистических понятий. В задачу данной книги не входит их углубленное обсуждение или описание вычислительных процедур. Существует множество хороших учебников по психологической статистике, и студентам для более полного понимания деталей необходимо ознакомиться с ними2. Тем не менее раскрыть сущность двух статистических понятий, играющих важнейшую роль в дифференциальной психологии, а именно, статистической значимости и корреляции, будет полезно.
2 Краткое введение в психологическую статистику не так давно было опубликовано Гарреттом (14). Для более детального ознакомления мы рекомендуем учебники Гарретта (15), Гилфорда (18) и Мак-Немара (21), содержащие сведения о более современных исследованиях в этой области.
Уровни статистической значимости. Понятие статистической значимости относится, прежде всего, к степени воспроизводимости сходных результатов при повторном исследовании. Насколько вероятно, что при повторном исследовании той же проблемы изначальный вывод может быть изменен на противоположный? Очевидно, что этот вопрос является фундаментальным для любого исследования. Одна из причин ожидаемого несоответствия между новыми результатами и прежними заключается в отклонениях, связанных с выборкой. Такие «случайные отклонения», вызывающие неконтролируемые флуктуации в данных, возникают оттого, что исследователь в состоянии задействовать только выборку из общей популяции, которой данное исследование может касаться.
Например, если исследователь захочет узнать рост 8-летних американских детей, то он может измерить 500 8-летних мальчиков, живущих на территории всей страны. Теоретически выборка для этой цели должна быть совершенно случайной. Таким образом, если у него есть имя каждого 8-летнего мальчика, он должен, выписав эти имена отдельно, вытаскивать их по жребию до тех пор, пока не наберет 500 имен. Или он может расположить все имена по алфавиту и выбрать каждое десятое. Случайной выборкой является такая, в которой у всех индивидов есть равные шансы в нее попасть. Это условие подразумевает, что каждый выбор не зависит от остальных. Например, если процедура выбора предполагала исключение всех родственников, то результирующую выборку нельзя признать в полной мере случайной.
Вероятнее всего, что на практике исследователь будет создавать репрезентативную выборку, утверждая, что состав его группы соответствует составу всей популяции 8-летних мальчиков, учитывая такие факторы, как соотношение живущих в городе и сельской местности, соотношение проживающих в разных районах страны, социоэкономический уровень, тип школы и т.п. В любом случае значение роста у членов выборки может быть лишь сугубо приблизительным по отношению к значению, характеризующему всю популяцию, они не могут быть тождественны. Если повторить эксперимент и набрать новую группу из 500 8-летних американских мальчиков, то полученное значение их роста будет так же отличаться от значения, полученного в первой группе. Именно эти случайные отклонения составляют то, что известно как «ошибка выборки».
Существует еще одна причина, по которой случайные отклонения могут влиять на наши результаты. Если мы измерим скорость бега группы детей, а затем повторим эти измерения в той же группе на следующий день, то, вероятно, получим несколько иные результаты. Может случиться так, что некоторые дети, которые были усталыми во время забега в первый день, обрели спортивную форму во время забега во второй день. В случае неоднократного повтора забегов и измерений скорости бега случайные отклонения будут представлять собой некое усредненное значение. Но результаты измерений в каждый отдельный день могут быть и очень высокими, и очень низкими. В этом случае мы можем рассматривать их в каждый отдельный день как то, что в совокупности составляет «популяцию» измерений, которые можно сделать в одной и той же группе.
Оба типа случайных отклонений могут оцениваться посредством применения измерения уровня статистической значимости. Существуют доступные формулы для вычисления достоверности значений, различий между значениями, изменчивости измерений, корреляций и многих других показателей. С помощью этих процедур мы можем предсказывать возможные пределы, в рамках которых наши результаты могут изменяться вследствие случайных отклонений. Важным элементом всех этих формул является количество случаев в выборке. При прочих равных обстоятельствах, чем больше выборка, тем более стабильными будут результаты, поэтому в больших группах случайных отклонений почти нет.
Одна из наиболее общих проблем достоверности измерений в дифференциальной психологии связана с тем, насколько существенна разница между двумя полученными значениями. Достаточно ли она велика, чтобы считаться выходящей за пределы вероятностных границ случайных отклонений? Если ответ положительный, то можно сделать вывод, что разница статистически существенна.
Предположим, что по результатам вербального теста на сообразительность, показатель у женщин в среднем на 8 пунктов выше, чем показатель у мужчин. Чтобы оценить, насколько существенна эта разница, мы вычисляем уровень статистической значимости. Анализируя специальную таблицу, мы сможем увидеть, может ли быть случайной вероятность того, что результирующие значения одной группы превышают результирующие значения другой группы на 8 пунктов и более. Предположим, мы обнаружили, что эта вероятность, обозначаемая буквой р, составляет 1 из 100 (р = 0,01). Это означает, что если бы вербальная сообразительность не зависела от половой принадлежности и если бы мы должны были взять из популяции наугад 100 случайных мужчин и женщин, то только в одном случае мы бы имели несовпадение с полученным результатом. Поэтому можно сказать, что по половой принадлежности отличие существенно на уровне 0,01. Такое утверждение выражает уровень статистической значимости вывода. Таким образом, если исследователь сделал вывод о том, что полученные им результаты свидетельствуют о различии по половому признаку, вероятность, что он ошибается, составляет 1 из 100. И наоборот, вероятность, что он прав, составит, естественно, 99 из 100. Еще одним уровнем статистической значимости, часто фигурирующим в сообщениях, является р = 0,05. Это означает, что ошибка возможна в 5 случаях из 100, а статистически значимым сообщение будет в 95 случаях из 100.
Другой проблемой, для решения которой нам требуется соотношение со значением р, является анализ действенности некоего экспериментального условия, например эффективности назначения витаминных препаратов. Действительно ли успехи группы, члены которой принимали витамины, существенно выше, чем у группы, членам которой давали плацебо, или контрольные таблетки? Достигает ли разница между показателями у двух групп степени достоверности 0,01? Может ли эта разница быть результатом случайных отклонений чаще, чем в одном случае из ста?
Это относится и к двукратному тестированию тех же самых людей — до и после эксперимента, такого, например, как специальная программа подготовки. В этом случае мы также должны знать, насколько достигнутые результаты превышают ожидаемые случайные отклонения.
Необходимо добавить, что величина уровня статистической значимости не обязательно должна строго соответствовать — и на самом деле редко соответствует — точным значениям, таким как 0,05; 0,01, или 0,001. Если, например, исследователь хочет обозначить уровень статистической значимости 0,01, то это означает, что согласно сделанному им выводу вероятность случайного отклонения составляет один случай из ста или меньше этого. Поэтому когда сообщают величину р, то делают это в следующей форме: р меньше 0,05 или р меньше 0,01. Это означает, что вероятность ошибочности некоего вывода составляет меньше 5 случаев из 100, или соответственно меньше 1 случая из 100.
Корреляция. Другое статистическое понятие, которое должен знать студент, изучающий дифференциальную психологию, называется корреляцией. Оно выражает степень зависимости, или соответствия, между двумя сериями измерений. Например, мы можем захотеть узнать, насколько взаимосвязаны между собой результаты, полученные в двух разных тестах, таких как тест на способность считать и тест на механическую сообразительность, проведенных с одними и теми же людьми. Или проблема может заключаться в том, чтобы по одному и тому же тесту найти степень соответствия между результатами родственников, например, отцов и сыновей. А задачей другого исследования может быть выяснение корреляции результатов одних и тех же людей одним и тем же тестам, но проводимых в разное время, например, до и после каких-либо испытаний. Очевидно, что в дифференциальной психологии существует множество проблем, требующих проведения анализа данного типа.
Примером наиболее распространенного измерения корреляции является коэффициент корреляции Пирсона, который принято обозначать символом г. Этот коэффициент представляет собой единый индекс итоговой корреляции и ее знака в целом по группе. Он может варьироваться от +1,00 (абсолютно позитивная корреляция) до —1,00 (абсолютно негативная, или обратная, корреляция).
Корреляция +1,00 означает, что индивид получает самые высокие результаты в одной серии измерений и в другой серии измерений, а также и в остальных сериях, или, что индивид в двух сериях измерений все время занимает второе место, то есть в любом случае, когда по крайней мере дважды показатели индивида совпадают. С другой стороны, корреляция —1,00 означает, что высшие результаты, полученные в результате измерения в одном случае, сменяются низшими показателями, полученными в другом случае, то есть находятся в отношении обратной корреляции в целом по группе. Нулевая корреляция означает, что между двумя наборами данных отсутствует какая бы то ни было зависимость, или что в организации эксперимента что-то привело к хаотичному смешению показателей. Точно так же интерпретируется корреляция результатов разных индивидов, например, отцов и сыновей. Так, корреляция +1,00 будет означать, что у отцов, имеющих наивысшие показатели в группе, сыновья так же имеют наивысшие показатели, или отцы, занимающие второе место, имеют сыновей, так же занимающих второе место, и так далее. Знак коэффициента корреляции, положительный или отрицательный, показывает качество зависимости. Отрицательная корреляция означает обратное отношение между переменными. Числовая величина коэффициента выражает степень близости, или соответствия. Корреляции, выводимые в рамках психологических исследований, крайне редко достигают 1,00. Иными словами, данные корреляции не абсолютны (ни положительные, ни отрицательные), но отражают некоторую индивидуальную изменчивость внутри группы. Мы проявляем тенденцию к сохранению высоких результирующих значений, которая существует наряду с исключениями, имеющими место внутри группы. Результирующий коэффициент корреляции в числовом выражении будет находиться между 0 и 1,00.
Пример сравнительно высокой положительной корреляции дан на рисунке 1. Этот рисунок показывает «двухвариантное распределение», или распределение в двух вариантах. Первый вариант (данные по нему расположены в основании рисунка) представляет собой совокупность показателей, полученных во время первого испытания тестом «скрытых слов», в котором испытуемые должны были подчеркивать все напечатанные на пестром листе бумаги английские слова, состоящие из четырех букв. Второй вариант (данные по нему расположены по вертикальной оси) представляет собой совокупность показателей, полученных у тех же самых испытуемых в результате прохождения ими в 15-й раз того же самого теста, но другой его формы. Каждая счетная палочка на рисунке показывает результат одного из 114 испытуемых как по первоначальному тестированию, так и по пятнадцатому. Возьмем, к примеру, испытуемого, чьи начальные показатели находились в пределах от 15 до 19, а конечные — в промежутке между 50 и 54. Проделав необходимые вычисления, находим, что коэффициент корреляции Пирсона между этими двумя наборами значений составляет 0,82.
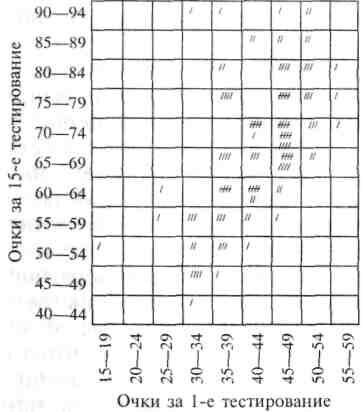
Рис. 1. Двухвариантное распределение результирующих значений 114 субъектов при первичном и окончательном тестировании на скрытые слова: корреляция = 0,82. (Неопубликованные данные Анастази, 1.)
Не вдаваясь в математические подробности, заметим, что данный метод корреляции основывается на учете каждого случая отклонения результирующего значения индивида от группового значения в обоих вариантах. Таким образом, если значения у всех индивидов окажутся намного выше или намного ниже группового значения, как при первом, так и при последнем тестировании корреляция составит +1,00. Легко заметить, что рисунок 1 не показывает такого однозначного соответствия. В то же время, гораздо больше счетных палочек расположено на диагонали, соединяющей левый нижний и правый верхний углы. Такое двухвариантное распределение показывает высокую положительную корреляцию, здесь нет таких индивидуальных значений, которые были бы очень низкими при первом и очень высокими при последнем тестировании или очень высокими в первом и очень низкими в последнем случае. Коэффициент 0,82 по существу показывает, что есть явная тенденция испытуемых к сохранению своего относительного положения в группе как в начале, так и в конце испытаний.
Анализируя множество случаев, в которых подсчитывалась корреляция, мы можем оценить статистическое значение полученного коэффициента г теми методами, о которых говорилось в начале данного раздела. Таким образом, при анализе 114 случаев г = 0,82 будет существенным на уровне 0,001. Это означает, что ошибка могла бы возникнуть в результате такого случая, вероятность которого была бы менее чем один вариант из тысячи. Именно на этом основана наша убежденность в том, что результаты действительно коррелируют друг с другом.
Кроме методики вычисления пирсоновского коэффициента корреляции, существуют и другие методы измерения корреляции, применимые в особых ситуациях. Например, когда в соответствии с результатами составляется список испытуемых или их распределяют по нескольким категориям на основании соответствующих признаков, корреляцию между признаками можно вычислить по другим формулам. Результирующие коэффициенты при этом будут так же выражаться числом от 0 до 1,00 и могут интерпретироваться примерно так же, как г Пирсона.
Бурно развивающаяся статистика обогатила дифференциальную психологию не только такими понятиями, как статистическое значение и корреляция, но и многими другими понятиями и методиками. Понятия статистическое значение и корреляция были выделены нами потому, что мы, обратившись к ним с самого начала, будем использовать данные понятия почти в каждой теме. Так, в главе 2 мы будем рассматривать распределение отклонений и измерение изменчивости. А методы факторного анализа, дающие возможность дальнейшего анализа коэффициентов корреляции, будут рассматриваться нами в связи с исследованием конфигурации признаков (гл. 10).










